Big V Wu Enda once said: doing AI research is like building a spaceship. In addition to sufficient fuel, a strong engine is also essential. If the fuel is insufficient, the spacecraft cannot enter the intended orbit. The engine is not strong enough, and the spacecraft can't even take off. Analogous to AI, the deep learning model is like an engine, and the massive training data is like fuel, both of which are equally indispensable for AI.
Deep learning is a research field that has received much attention in recent years and plays an important role in machine learning. Deep learning enables the interpretation of external data by performing feature extraction of externally input data from low-level to high-level features by building and simulating the hierarchical structure of the human brain.

Deep learning
The concept of Deep Learning stems from the study of artificial neural networks. A multilayer perceptron with multiple hidden layers is a deep learning structure.
Deep learning, also known as Deep Structured Learning, Hierarchical Learning, or Deep Machine Learning, is a collection of algorithms that are a branch of machine learning. It attempts to model a high-level summary of the data.
Machine learning uses algorithms to allow the machine to learn the rules from a large amount of data input from the outside world, so that recognition and judgment can be made. The development of machine learning has experienced two waves of shallow learning and deep learning. Deep learning can be understood as the development of neural networks. The neural network abstracts and models the basic characteristics of the human brain or biological neural network. It can learn from the external environment and adapt to the environment in a similar way to the biological interaction. Neural networks are an important part of the intelligent discipline and provide an effective way to solve complex problems and intelligent control. Neural networks have once become the focus of attention in the field of machine learning.
Let's use a simple example to illustrate that you have two sets of neurons, one that accepts the input and one that sends the output. When the input layer receives the input signal, it makes a simple modification of the input layer and passes it to the next layer. In a deep network, there can be many layers between the input layer and the output layer (these layers are not composed of neurons, but it can be understood in terms of neurons), allowing the algorithm to use multiple processing layers, and Linear and non-linear transformations are performed on the results of these layers.
The origin of deep learning
1. Enlightenment of human brain vision mechanism
Humans are faced with a large amount of sensory data all the time, but the brain can always capture important information easily. The core problem of artificial intelligence is to imitate the brain's ability to express information efficiently and accurately. Through research in recent years, we have some understanding of the brain mechanism, which has promoted the development of artificial intelligence.
Neurological studies have shown that the information processing of the human visual system is hierarchical, extracting edge features from the lower V1 region, to the shape of the V2 region, and then to the higher layers. When the human brain receives an external signal, it does not directly process the data, but acquires the law of the data through a multi-layer network model. This hierarchical perception system greatly reduces the amount of data that the vision system needs to process and preserves the useful structural information of the object.
2. Limitations of existing machine learning
Deep learning is relative to shallow learning. Nowadays, many learning methods are shallow structure algorithms. They have certain limitations. For example, the ability to represent complex functions is limited when the sample is limited, and the generalization ability is limited for complex classification problems.
Deep learning can learn a deep nonlinear network structure, realize complex function approximation, characterize the distributed representation of input data, and learn the essential features of the data set in the case of few sample sets.
Although shallow learning is widely used, it is only effective for simple calculations and does not reach the response of the human brain. This requires deep machine learning. All of these indicate that shallow learning networks have great limitations and have inspired our research on deep network modeling.
Deep machine learning is the inevitable result of distributed representation of data. A learner obtained by a learning algorithm with many learning structures is a local estimation operator. For example, a learner constructed by a kernel method is constructed by weighting the matching degree of a template. For such problems, we usually have reasonable assumptions, but when the objective function is very complicated, the number of regions that need to be described by parameters is also huge, so such model generalization ability is very poor. Distributed representations can handle dimensionality catastrophes and local generalization constraints in machine learning and neural network research. Distributed representation not only describes the similarity between concepts well, but also the appropriate distributed representation can show better generalization performance under limited data. Understanding and processing the received information is an important part of human cognitive activities. Because the structure of these information is generally complex, it is constructed.
It is necessary to have a deep learning machine to realize some human cognitive activities.
3, the need for feature extraction
Machine learning uses algorithms to allow the machine to learn the rules from a large amount of data input from the outside world, so that recognition and judgment can be made. The general flow of machine learning in solving problems such as image recognition, speech recognition, and natural language understanding is shown in Figure 1.
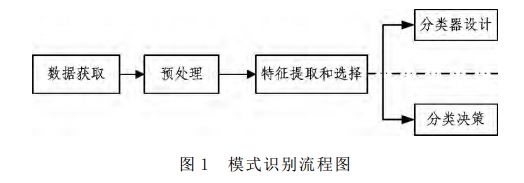
The data is first obtained by sensors, then subjected to preprocessing, feature extraction, feature selection, and then to reasoning, prediction, and recognition. Good feature expression affects the accuracy of the final algorithm, and the main calculation and testing work of the system is in this part. This link is generally done manually. It is a very laborious method to extract features by hand. It does not guarantee the quality of the selection, and its adjustment requires a lot of time. However, deep learning can automatically learn some features, and no one needs to participate in the feature selection process.
Deep learning is a multi-level learning. As shown in Figure 2, it is impossible to achieve similar effects to the human brain with fewer hidden layers. This requires multiple layers of learning, learning layer by layer and passing the knowledge of learning to the next level. In this way, the input information can be hierarchically expressed. The essence of deep learning is to extract external, input sound, image, text and other data from low-level to high-level features by establishing and simulating the hierarchical structure of the human brain, so that external data can be interpreted. Compared with the traditional learning structure, deep learning emphasizes the depth of the model structure, usually contains multiple layers of hidden layer nodes, and in deep learning, feature learning is crucial, and the final prediction and recognition are completed through layer-by-layer transformation of features.
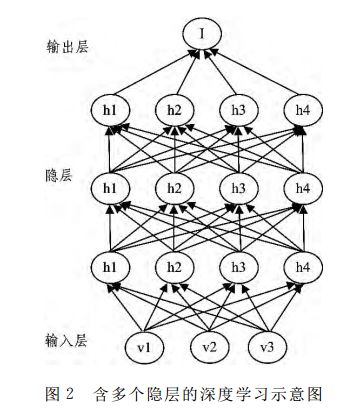
Classical algorithm for deep learning
As a branch of machine learning, deep learning can be divided into supervised learning and unsupervised learning. Both methods have their own unique learning models: multi-layer perceptron, convolutional neural network, etc. belong to supervised learning; deep confidence network, automatic encoder, denoising autoencoder, sparse coding, etc. belong to unsupervised learning.
1. Supervised learning: Convolutional neural network CNNs
In the 1960s, Hubel and Wiesel proposed the concept of a receptive field through the study of cat visual cortical cells. Inspired by this, Fukushima proposed that the neural cognitive machine (neocognitron) can be regarded as the first implementation network of the CNNs convolutional neural network, and it is also the first application of the receptive field concept in the field of artificial neural networks. LeCun et al. then designed and used a gradient-based algorithm to train the convolutional neural network, and it exhibited leading performance relative to other methods at the time in some pattern recognition tasks. Modern physiology's understanding of the visual system is also consistent with the image processing process in CNNs, which lays the foundation for the application of CNNs in image recognition. CNNs is the first robust deep learning method to successfully adopt a multi-layer hierarchical network. By studying the spatial correlation of data, the number of training parameters is reduced. At present, in the field of image recognition, CNNs have become an efficient method of identification.
CNNs are a multi-layered neural network. As shown in Figure 3, each layer consists of multiple two-dimensional planes, each of which consists of multiple independent neurons. A set of local units in the upper layer is used as input to the next adjacent unit. This local connection view originated from the perceptron. The externally input image is convoluted by a trainable filter plus offset. After convolution, three feature maps are generated at the C1 layer; then each set of pixels in the feature map is summed and offset, and then passed through Sigmoid. The function obtains the feature map of the S2 layer; these maps then obtain the C3 layer through the filter; C3 is similar to S2, and then generates S4; finally, these pixel values ​​are rasterized and connected into a vector input to the neural network, thereby obtaining The output. Generally, the C layer is a feature extraction layer, and the input of each neuron is connected with the local receptive field of the previous layer, and the local feature is extracted, and the positional relationship between it and other feature spaces is determined according to the local feature; the S layer is a feature The mapping layer has a displacement invariance. Each feature is mapped to a plane. The weights of all neurons on the plane are equal, thus reducing the number of free parameters of the network and reducing the complexity of network parameter selection. Each feature extraction layer (C layer) is followed by a calculation layer (S layer) for local averaging and secondary extraction. This constitutes the structure of the two feature extractions, so that when the input samples are identified, the network has Very good distortion tolerance. For each neuron, the corresponding accepted domain is defined, which only accepts signals from the self-accepting domain. Multiple mapping layers are combined to obtain the relationship between the layers and the information on the airspace, thereby facilitating image processing.
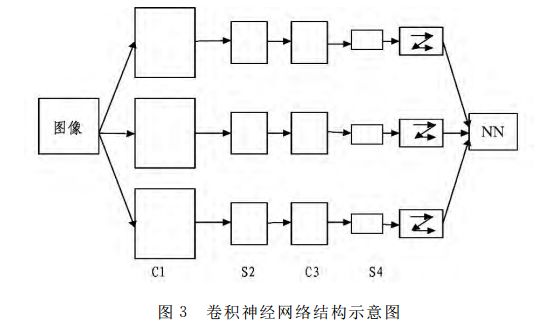
CNNs is a kind of artificial neural network, which has strong adaptability and is good at mining local features of data. Its weight-sharing network structure makes it more similar to biological neural networks, which reduces the complexity of the network model and reduces the number of weights, making CNNs applied in various fields of pattern recognition and achieving good results. CNNs optimize the network structure by combining local sensing regions, shared weights, spatial or temporal downsampling to make full use of the local features contained in the data itself, and to ensure a certain degree of displacement invariance. The LeNet model from LeCun has achieved good results when applied to various image recognition tasks and is considered to be one of the representatives of the general image recognition system. Through these years of research work, CNNs are increasingly used, such as face detection, document analysis, voice detection, and license plate recognition. In 2006, Kussul et al. proposed a neural network using permutation coding technology to achieve performance comparable to some specialized classification systems in recognition tasks such as face recognition, handwritten digit recognition and small object recognition; and in 2012, researchers The continuous frame in the video data is used as the input data of the convolutional neural network, so that the data in the time dimension can be introduced to recognize the motion of the human body.
2, unsupervised learning: deep confidence network DBNs
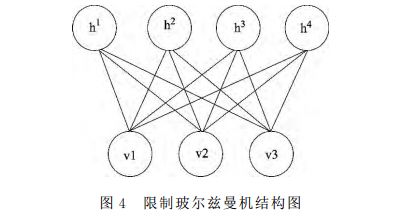
DBNs are a deep learning structure that is widely studied and applied at present, and it is accumulated by multiple restricted Boltzmann machines. The RBM structure is shown in Figure 4. It is divided into a visible layer, that is, an input data layer (Ï…) and a hidden layer (h). There is no connection between nodes of each layer, but layers and layers are interconnected with each other. Compared to the traditional sigmoid belief network, RBM is easy to connect to the learning of weights. Hinton et al. believe that if a typical DBN has one hidden layer, then the joint probability distribution can be used to describe the relationship between the input data and the implicit vector:

among them, 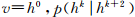 Is a conditional probability distribution. In the process of DBN learning, what is to be learned is the joint probability distribution. In the field of machine learning, the meaning of joint probability distribution is the generation of objects.
Is a conditional probability distribution. In the process of DBN learning, what is to be learned is the joint probability distribution. In the field of machine learning, the meaning of joint probability distribution is the generation of objects.
The traditional BP algorithm is widely used in the classical network structure, but it has encountered many difficulties for the training of deep learning. First, the BP algorithm is supervised learning, and the training needs a sample set with labels, but the actual data can be obtained. Unlabeled; Second, the BP algorithm has a slow learning process in the learning structure of multiple hidden layers; third, inappropriate parameter selection leads to local optimal solutions. In order to obtain the generating weight, the pre-training adopts the unsupervised greedy layer-by-layer algorithm, and the unsupervised greedy layer-by-layer training algorithm is proved to be effective by Hinton.
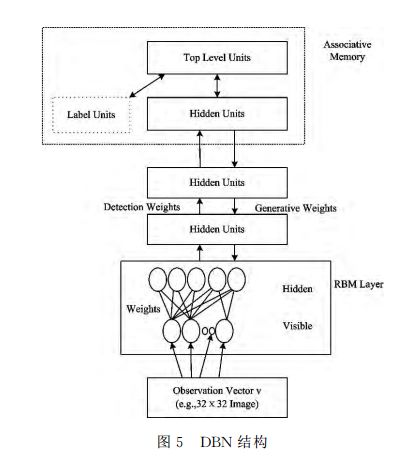
The core idea of ​​the unsupervised greedy layer-by-layer training algorithm is: layering the DBN (see Figure 5), unsupervised learning at each level, training only one layer at a time, using the results as a higher level of input, and finally using supervision Learn to adjust all layers. In this training phase, first, a vector v is generated in the visible layer, by which values ​​are mapped to hidden cells; then, the input of the visible layer is randomly selected to attempt to reconstruct the original input signal; These new visual units are mapped to the hidden unit again to obtain a new hidden unit h. Performing this iterative step is called Gibbs sampling. The correlation difference between the hidden layer activation unit and the visual layer input is used as the main basis for weight update. At the top two levels, the weights are joined together so that the output of the lower layer will provide a reference clue or association to the top layer so that the top layer will link it to its memory content. After the pre-training, the DBN can use the tagged data and BP algorithm to adjust the performance of the network structure. The BP algorithm of DBNs only needs to perform a local search on the weight parameter space. Compared with the forward neural network, the training time is significantly reduced. The training RBM is an effective random sampling technique of Gibbs. In the process of greedy learning algorithm, the basic idea of ​​Wake-Sleep algorithm is adopted. In the Wake stage, the algorithm uses the weights obtained by learning to provide data for the next layer of training in the bottom-up order. In the Sleep phase, according to the self. The top-down order uses weights to reorganize the data.
DBNs are deep learning structures that are widely researched and applied. Because of their flexibility, they are easy to expand. For example, convolution DBNs are an extension of DBNs, which has brought breakthroughs in speech signal processing. As an emerging generation model, DBNs have been widely used in object modeling, feature extraction, and recognition.
Deep learning application
In practical applications, many problems can be solved through deep learning. So let's give some examples:
Black and white image coloring
Deep learning can be used to color pictures based on objects and their context, and the results are much like human coloring results. This solution uses a large convolutional neural network and a supervised layer to recreate the color.
machine translation
Deep learning translates unprocessed language sequences, allowing algorithms to learn the dependencies between words and map them into a new language. A large-scale LSTM RNN network can be used for this type of processing.
Object classification and detection in images
This kind of task requires dividing the image into one of the categories we know before. The best result of this type of task is currently achieved using a very large scale convolutional neural network. The breakthrough development is the AlexNet model used by Alex Krizhevsky and others in the ImageNet competition.
Automatically generate handwriting
This task is to first give some handwritten text and then try to generate new similar handwritten results. The first is that people use pens to write some text on paper, then train the model according to the handwriting of the writing, and finally learn to produce new content.
Automatic game play
This task is based on the image of the computer screen to decide how to play the game. This difficult task is the research area of ​​the deep reinforcement model, and the main breakthrough is the result of the DeepMind team.
Chat robot
A sequence to sequence based model to create a chat robot to answer certain questions. It is generated from a large number of actual session data sets.
Although there are still many problems in the study of deep learning, its impact on the field of machine learning cannot be underestimated. More complex and more powerful depth models can reveal the information carried in big data and make more accurate predictions of future and unknown events. In short, deep learning is an area worth studying and will definitely become more mature in the next few years.
The latest Windows has multiple versions, including Basic, Home, and Ultimate. Windows has developed from a simple GUI to a typical operating system with its own file format and drivers, and has actually become the most user-friendly operating system. Windows has added the Multiple Desktops feature. This function allows users to use multiple desktop environments under the same operating system, that is, users can switch between different desktop environments according to their needs. It can be said that on the tablet platform, the Windows operating system has a good foundation.
Windows Tablet,New Windows Tablet,Tablet Windows
Jingjiang Gisen Technology Co.,Ltd , https://www.jsgisengroup.com